Whitepaper · Aether AI
Unlimited Context: Virtual Memory for LLM Attention
How any local large language model gets billion-token reach by encoding overflow to a local pool and paging the right slice back — instead of compress-and-forget.
aether-context — that gives any local LLM (via Ollama, llama.cpp, or Hugging Face) reach over roughly a billion tokens of context. When the model's window fills, it does not summarize and discard the overflow. It encodes the overflow into a local, memory-mapped vector pool on disk and pages the relevant slice back into the working window exactly when the model needs it — concurrently with generation. It is virtual memory, for an LLM's attention.
⭐ Star on GitHub pip install aether-context
The problem: long runs rot in the middle
Every long agentic run dies the same way. The model fills its context window, begins compressing its own history to make room, and silently drops the one detail that mattered three steps ago. Then it drifts — the runaway pull request, the agent that confidently rewrites a function it already wrote, the build that falls apart at hour two.
Bigger windows only delay the failure. A crammed million-token window suffers from "lost in the middle": transformer models reliably use information at the start and end of a long context far better than information buried in the middle, so a stuffed window quietly degrades even when nothing has been dropped [1]. Two forces compound: compaction loss (summarizing throws away specifics) and positional rot (mid-context facts are under-attended).
The fix: encode & recover, not compress & forget
Unlimited Context fixes the overflow, not the window. Instead of blindly summarizing what spills over, it encodes and externalizes it to a local pool, and retrieves the right slice back on demand. Nothing load-bearing is silently lost — it is filed, and recoverable.
Compress & forget ✗ → Encode & recover ✓
How it works: virtual memory for attention
The cleanest way to understand the architecture is to map it onto an operating system's virtual memory:
| OS concept | Unlimited Context |
|---|---|
| RAM (small, fast) | Resident window — what the model sees this turn |
| Disk (vast, cheap) | Context pool — a memory-mapped vector index on disk, ~5 GB, ~1B tokens |
| Pager | Slice loader — prefetches the next slice from what the model is reasoning about right now, on a background thread |
| Page replacement | Retention policy — useful slices stay, stale ones fade, anything relevant again comes back |
| Encode-on-spill | Encoder — turns overflow into compact retrieval vectors as it streams |
Because the pager runs concurrently with generation — hidden behind the model's own thinking — reaching the pool adds no extra wall-clock latency. The retrieval is effectively free in time; what it costs is disk, and a good retrieval hit rate, which the loader is engineered to keep high.
The five moving parts
- Encoder — a fast, local, stateless embedder that turns spilled text into compact retrieval vectors as it streams; no GPU, no network, no model download.
- Context pool — a session-namespaced, memory-mapped vector store with a hard size budget. Vectors live on disk; only the index and a hot working set are ever resident in RAM.
- Slice loader (pager) — fetches the slices the model is most likely to need next into a warm cache, and tracks its hit rate.
- Retention — decides what stays reachable: useful slices stay, stale ones fade, anything relevant again comes back; under budget pressure the least-valuable slices are evicted first.
- Session — the lifecycle controller: open a fresh window, stream-encode-and-fade as the model emits, reason over a paged window, then close.
Unlimited Context vs. the alternatives
Long-context approaches make different trade-offs. The comparison below is the fast way to place Unlimited Context against the four common strategies developers reach for.
| Approach | Reach | Loses detail? | Cost model | Local / private |
|---|---|---|---|---|
| Unlimited Context | ~1B+ tokens (per 5 GB) | No — encoded & recoverable | Disk + retrieval (one-time encode) | Yes — fully local |
| Bigger context window | Up to model limit (e.g. 1M) | No, but rots in the middle [1] | Quadratic-ish compute & $ per token | Depends on model |
| Summarization / compaction | Unbounded in theory | Yes — specifics discarded | Extra LLM calls per compaction | Depends |
| Vector RAG (static corpus) | Corpus size | No, but not the model's own working memory | Embedding + store | Yes, if self-hosted |
| Fine-tuning | Baked into weights | N/A (not per-run memory) | Training compute | Yes, if local |
The key distinction: Unlimited Context is the only one that continuously externalizes and recovers the model's own live overflow during a single long run, rather than pre-loading a fixed corpus or throwing detail away.
Benchmarks: a real, paid run — not a slogan
The headline benchmark is a real, paid, end-to-end run, committed to the repository. A reasoning model — deepseek-v4-pro, via OpenRouter — was driven through a 40-turn agent session that overflows its context window (a deliberately small 2,000-token window, working 60 real microsoft/vscode GitHub issues), measured with the engine off versus on. One live run, total spend $0.19, June 14, 2026.
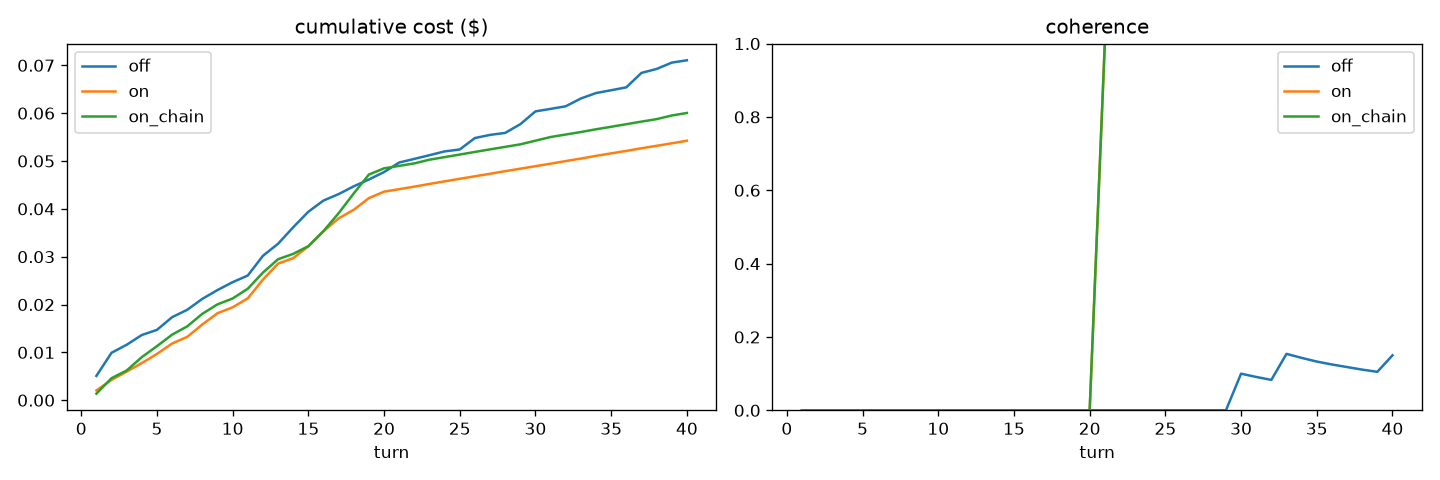
Three results, straight from the run:
- The model stops forgetting. Recall coherence of early facts after they fall out of the window: 0.15 → 1.00 (6.7×). The baseline drifts and forgets; the engine holds every early fact, with zero drift.
- Failure turns into success on the real work. Tasks completed correctly: 3 / 20 → 20 / 20. The job is only done right with the engine.
- Cheaper, not just better. −24% total session cost, −54% in the recall back-half — the engine sends a compact recalled slice instead of dragging the whole transcript into every call.
| Metric | Off (baseline) | On (engine) | Change |
|---|---|---|---|
| Recall coherence (early facts still correct) | 0.15 | 1.00 | 6.7× |
| Work outcome (tasks done right) | 3 / 20 | 20 / 20 | 3 → 20 |
| Cost — full session | $0.0711 | $0.0542 | −24% |
| Cost — back half (recall phase) | $0.00117/turn | $0.00053/turn | −54% |
Scope, honestly: this measures the engine (retrieve-on-overflow memory). The 2,000-token window is deliberately tiny to force overflow, so a realistic window shows a smaller — still real — gain. N = 20 recall turns, single run, supervised under a $25 hard cap. Committed data and the exact reproduce command live in the repository: python -m bench.api_eval --model deepseek/deepseek-v4-pro --repo microsoft/vscode --arms off,on --plot.
A second, hermetic benchmark proves the mechanism offline in CI with no API spend: python bench/drift_vs_window.py --model ollama/qwen2.5 runs the same base model on a long scripted build, engine on vs off, and reports drift, per-stage correctness, retrieval hit rate, and unattended completion.
The numbers behind the reach
"Billion-token memory" is derived, not a slogan. Each encoded slice is ~2.2 KB (a compact vector plus compressed text and metadata) and represents ~512 tokens. That works out to roughly 455,000 slices per gigabyte → ~233 million tokens of reach per gigabyte, so reach ≈ pool_GB × 233M.
| Pool | Encoded reach | Resident index RAM |
|---|---|---|
| 5 GB (floor) | ~1.16B tokens | ~146 MB |
| 10 GB | ~2.33B tokens | ~291 MB |
| 20 GB | ~4.65B tokens | ~582 MB |
RAM stays predictable because vectors are memory-mapped on disk: RAM ≈ 180 MB base + 29 MB per GB of pool + 30 MB per session. A bigger pool buys reach, not concurrent sessions — those are RAM-bound either way.
Quickstart
pip install aether-contextfrom aether_context import Session
s = Session(model="ollama/qwen2.5", pool_gb=5)
s.run("Build me a full-stack weightlifting tracker app.")
# runs long. stays coherent. walk away.The core install is numpy-only and works offline; the Ollama path uses only the Python standard library. llama.cpp and Hugging Face Transformers are opt-in extras (pip install "aether-context[llamacpp]" / [hf]). No GPU, API key, or account required.
Who it's for
- Local-LLM developers running Llama, Qwen, Mistral, or Phi who want long, coherent agentic runs without a frontier API bill.
- Agent builders whose autonomous loops drift after an hour because the window compacts.
- Privacy-first teams who need context that never leaves the machine.
Frequently asked questions
What is Unlimited Context?
An open-source engine (aether-context) that gives any local LLM billion-token reach by encoding window overflow to a local on-disk vector pool and paging the right slice back while the model reasons — virtual memory for attention.
How is it different from RAG?
RAG retrieves from a static external corpus before generation. Unlimited Context continuously encodes the model's own live working memory during a run and pages it back concurrently with generation.
Does it run locally and offline?
Yes — numpy-only core, no API key or account, wrapping Ollama, llama.cpp, or Hugging Face. A 5 GB pool holds ~1.16B tokens of encoded reach on disk.
Does "unlimited" mean an infinite attention window?
No. It means reach, not attention. The model keeps its native window; the engine lets it reach a billion-token pool in slices via fast retrieval. Quality rides on retrieval hit rate.
What does it cost?
It's free and open-source under Apache-2.0. The only cost is local disk for the pool.
About the authors
Aether AI, founded by Brandon Barrante, builds local-first, verifiable AI infrastructure. Unlimited Context is the open engine in that stack; the hosted Aether platform layers verified knowledge and frontier-model routing on top of the same engine. Unlimited Context is released as open source under Apache-2.0 at github.com/DBarr3/Unlimited-Context-LLM.
References
- Liu, N. F., et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. arXiv:2307.03172.
- Aggarwal, P., et al. (2024). GEO: Generative Engine Optimization. Proceedings of KDD 2024.
- Aether AI (2026). aether-context — open-source context engine, Apache-2.0. github.com/DBarr3/Unlimited-Context-LLM.
© 2026 Aether AI · Brandon Barrante. Unlimited Context and aether-context are released under the Apache-2.0 license. aethersystems.net